
捷速OCR文字识别软件是一款专业的图像文字识别软件,提供图片文字识别、扫描文字识别、pdf文字识别、图像识别等文字识别服务,并且可以批量转换。采用先进的精准识别技术,识别正确率高,识别速度快,对图文混排文档可自动解析,强大的文字识别纠错技术,完美还原文档结构和格式,无需重新排版。它可将你上传的图片转换成WORD、图片转换成文字等可编辑文字,一键转换,OCR识别在线超快!支持JPG、PNG、GIF、BMP、DOC等图片格式,捷速OCR文字识别软件支持:OCR识别在线上传图片转换文本,OCR文字识别,OCR文字识别软件,图片转换成WORD,图片转换成文字,pdf文字识别。软件可可以直接识别文字,将图像转化成文字的工具。很多时候我们需要一款软件能够直接把扫描文件上面的文字的变成直接可以编辑的文字,这样我们工作就方便很多了,可以直接使用扫描仪扫描书籍和相关的文档,然后使用捷速扫描文字识别软件,就可以编辑这些文字,能够节省我们办公人员很多的时间,这些软件特别是对那些处理文档的人员和相关的从事编辑行业的人员特别适用,可以广泛的应用,并且软件识别正确率高,可以批量的转换扫描的文件,是一款不可多得的扫描文字识别软件!
# 破解文档限制:即单个文档大小转换无限制;
# 破解高级识别:3次免费试用机会限制,每次识别后保存次数无限制;
# 破解极速识别:非VIP用户只能识别前五页的文档转换限制,可转换完整内容。
# 破解票证识别:每天识别10个限制,识别数量无限制,重启软件循环操作即可;
已知小问题:票证识别的【一键识别】点击无反应,需要手动点击【开始识别】。
2、完美还原文档格式:软件可一键读取文档,完美还原文档的逻辑结构和格式,无需重新录入和排版。
3、自动解析图文版面:软件对图文混排的文档具有自动分析功能,将文字区域划分出来后自动进行识别。
4、极速识别文本内容:软件具备高智能化识别内核,通过智能简化软件使用的操作步骤,实现极速识别。
5、强大识别纠错技术:软件提供更强大的文字识别纠错技术,精准地检测出文档样式、标题等内容。
6、改进图片处理算法:软件进一步改进图像处理算法,提高扫描文档显示质量,更好地识别拍摄文本
2、扫描一幅简单的印刷文档的图像,将每一个文字图像分检出来交给识别模块识别,这一过程称为图像预处理。预处理是指在进行文字识别之前的一些准备工作,包括图像净化处理,去掉原始图像中的显见噪声(干扰)。主要任务是测量文档放置的倾斜角,对文档进行版面分析,对选出的文字域进行排版确认,对横、竖排版的文字行进行切分,每一行的文字图像的分离,标点符号的判别等。这一阶段的工作非常重要,处理的效果直接影响到文字识别的准确率。
3、单字识别是体现OCR文字识别的核心技术。从扫描文本中分检出的文字图像,由计算机将其图形、图像转变成文字的标准代码,是让计算机“认字”的关键,也就是所谓的识别技术。就像人脑认识文字是因为在人脑中已经保存了文字的各种特征,如文字的结构、文字的笔画等。要想让计算机来识别文字,也需要先将文字的特征等信息储存到计算机里,但要储存什么样的信息及怎样来获取这些信息是一个很复杂的过程,而且要达到非常高的识别率才能符合要求。通常采用的做法是根据文字的笔画、特征点、投影信息、点的区域分布等进行分析。
4、后处理是指对识别出的文字或多个识别结果采用词组方式进行上下匹配,即将单字识别的结果进行分词,与词库中的词组进行比较,以提高系统的识别率,减少误识率。
破解内容
# 破解VIP,登陆即为已开通VIP身份永不过期;# 破解文档限制:即单个文档大小转换无限制;
# 破解高级识别:3次免费试用机会限制,每次识别后保存次数无限制;
# 破解极速识别:非VIP用户只能识别前五页的文档转换限制,可转换完整内容。
# 破解票证识别:每天识别10个限制,识别数量无限制,重启软件循环操作即可;
已知小问题:票证识别的【一键识别】点击无反应,需要手动点击【开始识别】。
软件功能
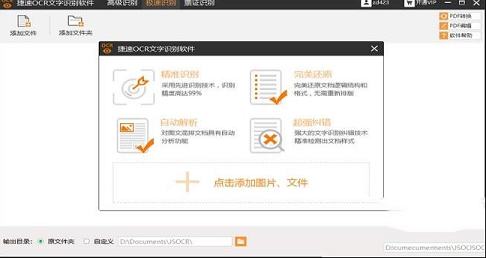
1、精准识别文字信息:软件采用先进的OCR识别技术,高达99%的识别精度,轻松实现文档数字化。2、完美还原文档格式:软件可一键读取文档,完美还原文档的逻辑结构和格式,无需重新录入和排版。
3、自动解析图文版面:软件对图文混排的文档具有自动分析功能,将文字区域划分出来后自动进行识别。
4、极速识别文本内容:软件具备高智能化识别内核,通过智能简化软件使用的操作步骤,实现极速识别。
5、强大识别纠错技术:软件提供更强大的文字识别纠错技术,精准地检测出文档样式、标题等内容。
6、改进图片处理算法:软件进一步改进图像处理算法,提高扫描文档显示质量,更好地识别拍摄文本
软件特点
1、是指通过输入设备将文档输入到计算机中,也就是实现原稿的数字化。现在用得比较普遍的设备是扫描仪。文档图像的扫描质量是OCR软件正确识别的前提条件。恰当地选择扫描分辨率及相关参数,是保证文字清楚、特征不丢失的关键。此外,文档尽可能地放置端正,以保证预处理检测的倾斜角小,在进行倾斜校正后,文字图像的变形就小。这些简单的操作,会使系统的识别正确率有所提高。反之,由于扫描设置不当,文字的断笔过多可能会分检出半个文字的图像。文字断笔和笔画粘连会造成有些特征丢失,在将其特征与特征库比较时,会使其特征距离加大,识别错误率上升。2、扫描一幅简单的印刷文档的图像,将每一个文字图像分检出来交给识别模块识别,这一过程称为图像预处理。预处理是指在进行文字识别之前的一些准备工作,包括图像净化处理,去掉原始图像中的显见噪声(干扰)。主要任务是测量文档放置的倾斜角,对文档进行版面分析,对选出的文字域进行排版确认,对横、竖排版的文字行进行切分,每一行的文字图像的分离,标点符号的判别等。这一阶段的工作非常重要,处理的效果直接影响到文字识别的准确率。
3、单字识别是体现OCR文字识别的核心技术。从扫描文本中分检出的文字图像,由计算机将其图形、图像转变成文字的标准代码,是让计算机“认字”的关键,也就是所谓的识别技术。就像人脑认识文字是因为在人脑中已经保存了文字的各种特征,如文字的结构、文字的笔画等。要想让计算机来识别文字,也需要先将文字的特征等信息储存到计算机里,但要储存什么样的信息及怎样来获取这些信息是一个很复杂的过程,而且要达到非常高的识别率才能符合要求。通常采用的做法是根据文字的笔画、特征点、投影信息、点的区域分布等进行分析。
4、后处理是指对识别出的文字或多个识别结果采用词组方式进行上下匹配,即将单字识别的结果进行分词,与词库中的词组进行比较,以提高系统的识别率,减少误识率。
更新日志
修改Bug∨ 展开
 msvcp100.dll
msvcp100.dll
 八方旅人1+2小斧头修改器 V23.8 最新免费版
八方旅人1+2小斧头修改器 V23.8 最新免费版
 SplitItv5.8.4859绿色免费版
SplitItv5.8.4859绿色免费版
 Raft幽灵辅助 V1.0 免费版
Raft幽灵辅助 V1.0 免费版
 editplus3v3.41中文破解版
editplus3v3.41中文破解版
 Font Awesomev5.14.0免费版
Font Awesomev5.14.0免费版
 火狐浏览器pcxFirefoxv53.0.3编译版
火狐浏览器pcxFirefoxv53.0.3编译版
 FWsim Prov3.1.1.6破解版
FWsim Prov3.1.1.6破解版
 美图秀秀PC破解版2022 V6.5.7.0 吾爱破解版
美图秀秀PC破解版2022 V6.5.7.0 吾爱破解版
 Retouch4me AI 11合1套装 V2023 中文破解版
Retouch4me AI 11合1套装 V2023 中文破解版
 Portraiture4完美中文汉化破解版 V4.0.3 最新免费版
Portraiture4完美中文汉化破解版 V4.0.3 最新免费版
 美图秀秀破解版吾爱破解2022电脑版 v.6.4.0.2绿色版
美图秀秀破解版吾爱破解2022电脑版 v.6.4.0.2绿色版
 剪映电脑版 V3.1.0.8712 官方PC版
剪映电脑版 V3.1.0.8712 官方PC版
 Naifu(二次元AI绘画生成器) V2022 最新版
Naifu(二次元AI绘画生成器) V2022 最新版
 Beauty Box插件v4.2.3汉化破解版(免序列号)
Beauty Box插件v4.2.3汉化破解版(免序列号)
 Disco Diffusion 5离线版 V3.5 本地运行版
Disco Diffusion 5离线版 V3.5 本地运行版