
汉王PDF OCR是汉王OCR 6.0和尚书七号的升级版,能识别多种字体并支持多种字体混排,可以自动判断、拆分、识别和还原各种通用型印刷体表格。本软件新增打开和识别PDF文件功能,支持文字型PDF的直接转换和图像型PDF的OCR识别,即可以采用PCR的方式将PDF文件转换为可编辑文档,也可以采用格式转换的方式直接转换文字型PDF文件为文本。目前,许多信息资料需要转化成电子文档以便于各种应用及管理,但因信息数字化处理的方式落后,不仅费时费力,而且资金消费巨大,造成了大量文档资料的积压,因此急需一种快速高效的软件系统来满足这种海量录入需求。本软件系统适用于个人、小型图书馆、小型档案馆、小型企业进行大规模文档输入、图书翻印、大量资料电子化的软件系统。
支持处理灰度、彩色、黑白三种色彩的BMP、TIF、JPG、PDF多种格式的图像文件;
可识别简体、繁体和英文三种语言;
具有简单易用的表格识别功能;
具有TXT、RTF、HTM和XLS多种输出格式,并有所见即所得的版面还原功能。
2.点击“文件”-“图像”(或直接按快捷键ctrl+O);
3.在弹出的对话框中选择PDF文件,此时下方的“pdf转换为TXT文件”或“pdf转换为RTF文件”将由灰变黑为可操作。
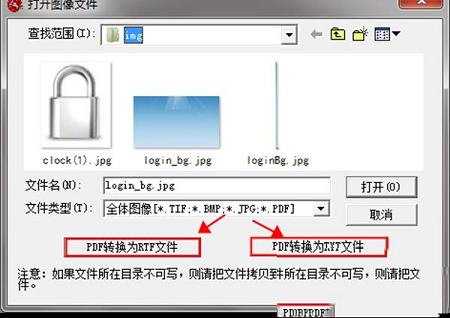
打开文件:按下“Ctrl+O”打开图像文件,追加图像文件。
保存图像:按下“Ctrl+S”键保存图像。
图像反白:按下“Ctrl+I”将图像反白。
自动倾斜校正:按下“Ctrl+D”进行自动倾斜校正。
手动倾斜校正:按下“Ctrl+M”进行手动倾斜校正。
版面分析:按下“F5”键,对选中的文件进行版面分析。
取消版面分析:按下“Ctrl+Del”键,取消当前页的版面分析。
1、可以,识别之前,在菜单或者工具栏里面设置一下是识别中文或英文。
二、为什么用汉王OCR识别的文字都是乱码?
1、可能是图片不清晰,扫描的时候调整一下分辨率。高级选项也可以设置一下大小。
三、用汉王PDF OCRV8.0 把pdf文件转换成TXT不成功?
因你的PDF文件是图形格式,不能直接转换(转换了也是空白的),需要用OCR识别。识别前进行OCR识别设置,语言和灰度设置。
使用方法:
1.打开汉王(设置),打开PDF文件,提示拆分页,确定,就自动识别页和拆分页。
2.再选择第1页,按住SHIFT,用鼠标滑动到最后一页,选择最后1页,相当于全部选择页;
3.按F8开始自动识别,会识别到 \My Documents\My Hwdoc Files\HWPDFOCR80\IMAGE 目录下;
4.因是按页识别的,要合并TXT文件。
在识别的TXT文件目录(\My Documents\My Hwdoc Files\HWPDFOCR80\IMAGE 目录下)下,建立一个纯文件文件,比如取名为:合并.TXT,改扩展名为BAT:合并.BAT
选择,鼠标右键,选择编辑,输入1个语句:
“copy *.txt 合并.txt”或“type *.txt >> 合并.txt”
两种方法都可以,选择一种就行,保存退出;双击这个批处理程序,就把当前目录下所有单页TXT文件,合并成1个TXT文件。记住只点击一次就行了,点击多了会重复合并。
识别完图片文字后导出时选择“输出”——“到指定格式文件”——选择“保存类型为RTF文件”,这样导出来就可以直接变成可编辑的WORD文件了,版面也一样。
软件特色
识别正确率高,识别速度快、批量处理功能;支持处理灰度、彩色、黑白三种色彩的BMP、TIF、JPG、PDF多种格式的图像文件;
可识别简体、繁体和英文三种语言;
具有简单易用的表格识别功能;
具有TXT、RTF、HTM和XLS多种输出格式,并有所见即所得的版面还原功能。
使用说明
1.首先直接打开“HWPDFOCR80.exe”汉王PDF OCR;2.点击“文件”-“图像”(或直接按快捷键ctrl+O);
3.在弹出的对话框中选择PDF文件,此时下方的“pdf转换为TXT文件”或“pdf转换为RTF文件”将由灰变黑为可操作。
快捷键
扫描文件:按下“Ctrl+N”调出扫描程序,扫描图像文件。打开文件:按下“Ctrl+O”打开图像文件,追加图像文件。
保存图像:按下“Ctrl+S”键保存图像。
图像反白:按下“Ctrl+I”将图像反白。
自动倾斜校正:按下“Ctrl+D”进行自动倾斜校正。
手动倾斜校正:按下“Ctrl+M”进行手动倾斜校正。
版面分析:按下“F5”键,对选中的文件进行版面分析。
取消版面分析:按下“Ctrl+Del”键,取消当前页的版面分析。
常见问答
一、汉王文字识别软件可以识别英文吗?1、可以,识别之前,在菜单或者工具栏里面设置一下是识别中文或英文。
二、为什么用汉王OCR识别的文字都是乱码?
1、可能是图片不清晰,扫描的时候调整一下分辨率。高级选项也可以设置一下大小。
三、用汉王PDF OCRV8.0 把pdf文件转换成TXT不成功?
因你的PDF文件是图形格式,不能直接转换(转换了也是空白的),需要用OCR识别。识别前进行OCR识别设置,语言和灰度设置。
使用方法:
1.打开汉王(设置),打开PDF文件,提示拆分页,确定,就自动识别页和拆分页。
2.再选择第1页,按住SHIFT,用鼠标滑动到最后一页,选择最后1页,相当于全部选择页;
3.按F8开始自动识别,会识别到 \My Documents\My Hwdoc Files\HWPDFOCR80\IMAGE 目录下;
4.因是按页识别的,要合并TXT文件。
在识别的TXT文件目录(\My Documents\My Hwdoc Files\HWPDFOCR80\IMAGE 目录下)下,建立一个纯文件文件,比如取名为:合并.TXT,改扩展名为BAT:合并.BAT
选择,鼠标右键,选择编辑,输入1个语句:
“copy *.txt 合并.txt”或“type *.txt >> 合并.txt”
两种方法都可以,选择一种就行,保存退出;双击这个批处理程序,就把当前目录下所有单页TXT文件,合并成1个TXT文件。记住只点击一次就行了,点击多了会重复合并。
识别完图片文字后导出时选择“输出”——“到指定格式文件”——选择“保存类型为RTF文件”,这样导出来就可以直接变成可编辑的WORD文件了,版面也一样。
∨ 展开
 Green Screen Wizard 11(照片背景去除软件)v11.3破解版
Green Screen Wizard 11(照片背景去除软件)v11.3破解版
 iThoughts windows破解补丁
iThoughts windows破解补丁
 ID3 renamer绿色版v7.2.7
ID3 renamer绿色版v7.2.7
 zbrush2021破解版 V2021.7 免费版
zbrush2021破解版 V2021.7 免费版
 Bixorama(全景照片转换工具)v5.4.0.3破解版(含安装教程+破解补丁)
Bixorama(全景照片转换工具)v5.4.0.3破解版(含安装教程+破解补丁)
 拳击之夜冠军修改器 V1.0 免费版
拳击之夜冠军修改器 V1.0 免费版
 IrfanViewv4.53绿色版
IrfanViewv4.53绿色版
 contextcapture17版 V10.18.00.232 官方版
contextcapture17版 V10.18.00.232 官方版
 福昕高级pdf编辑器12专业版 V12.0.0.12394 中文破解版
福昕高级pdf编辑器12专业版 V12.0.0.12394 中文破解版
 WPS2022专业增强版破解版 V11.8.2.11739 永久激活码版
WPS2022专业增强版破解版 V11.8.2.11739 永久激活码版
 Adobe Acrobat Pro DC 2018注册机/破解补丁(附破解教程)
Adobe Acrobat Pro DC 2018注册机/破解补丁(附破解教程)
 PDF-XChange Editor密钥破解版 V9.5.365.0 中文免费版
PDF-XChange Editor密钥破解版 V9.5.365.0 中文免费版
 WPS高级付费破解版电脑版 V11.8.2.11739 VIP免费版
WPS高级付费破解版电脑版 V11.8.2.11739 VIP免费版
 福昕高级PDF编辑器中文版免费破解版 V2023 无水印版
福昕高级PDF编辑器中文版免费破解版 V2023 无水印版
 汉王OCR(文字识别软件)v6.0破解版(附安装教程+破解补丁)
汉王OCR(文字识别软件)v6.0破解版(附安装教程+破解补丁)
 AI辅助写作纠错文本编辑工具 V0.1 免费版下载
AI辅助写作纠错文本编辑工具 V0.1 免费版下载