
AntiPlagiarism.NET是一款功能强大且操作简单的原创度检测工具,如果担心你的作品的原创性,你可以使用这个工具来检测片段并做出合理的修改。该软件能快速搜索出可在网上查询的非唯一文本片段,并能在短时间内检测出其唯一性。它还可以突出显示在原始文档和找到匹配项的网页中找到的文本的非唯一片段,并准确检测在每个可检查的web文档中找到的网页百分比的重复度。该软件采用搜索引擎进行自动检测,结果准确无误,使用方便,支持批量检验和网站检验,并提供丰富的高级选项,方便灵活的选择和设置,并支持多种格式。欢迎有需要的朋友前来下载体验。

2、双击Setup.exe运行,选择软件安装路径,点击next

3、安装完成,点击finish

4、将cracked中的Antiplagiarism.exe复制到安装目录中,点击替换目标中的文件

2、用百分比定义所谓的文本唯一性
3、在观察的文本和源网页的重新创建副本中突出显示重复的片段 编辑 页
4、发现肮脏的唯一性制作方法–这些方法包括用其他语言的相同字母替换字母,插入隐藏的utf符号
5、各种各样的搜索条件设置–样本大小,带状疱疹中的单词数等
6、预定义设置–“默认”,“快速”,“深度” 首选项-一般
7、定义URL页面和整个域的可能性,在检查过程中将被忽略 首选项-例外
8、手动输入或自动识别(通过API防盗门)搜索引擎验证码
9、使用代理列表(最大程度减少被搜索引擎阻止的可能性) 首选项-其他
10、保存检查结果的详细报告
.doc,.docx,.pdf,.odt,.html,.txt,.rtf-格式支持
11、简单直观的界面
12、“网站检查” –检查网站页面是否存在抄袭(您也可以在文本文件中指定地址列表) 网站检查
13、“批处理检查” –检查给定文件夹中的多个文件 批量检查
14、“本地检查” –从Windows OS索引的本地目录中检查文档是否存在抄袭 本地检查
15、“图像检查” –检查照片是否重复 图像检查
16、“文本比较” –定义两个文本之间的相似性 文字比较
17、“ Seo服务” –定义地址/域的SEO分析:检测Google Pr,Yandex TIC,Google和Yandex索引的页面数,在Yandex目录中的存在,DMOZ等) Seo服务
每年,越来越多的大学对项目和论文的原始文本提出更高的要求。此外,令人惊讶的是,不仅学生,而且还有太多的老师仍然不了解作品的原创性意味着什么。然而,学术诚信要求写作具有100%的新颖性,如今很难不让所有这些可用信息迷失。作者应注意不正确的引用,措辞和其他类似操作,以免得到可怕的结果。
2、学生抄袭检查器
在这种情况下,最好的解决方案是使用a窃检查器。它可以轻松地帮助用户省略工作中的相似部分,并消除所有可能的错误。除此以外,抄袭检测器是提高写作水平的绝好机会,它的构想新颖,结论精妙,因此更加有趣。为学生提供的抄袭软件可以保证获得百分百的成绩。否则,您可能会冒无法通过课程的风险,甚至会失去出色的职业机会。您最好尝试该程序并立即改善工作,而不要靠运气而错过成功的未来机会。
3、如何在线使用Pla窃检查器
独创性检查器的最佳功能是它可以24/7在线运行。这意味着您无需外出就可以找到出色的助手来撰写高质量的作品。在这里,您可以无限制地检查作业,然后老师才能对其进行检查。首先,这并不难。您只需要复制粘贴信息,然后单击“检查此文本”按钮即可。然后,该软件开始浏览各种资源以比较信息,因此您必须等待几秒钟。之后,程序将报告可能的窃事件,并突出显示它们。最后,您必须考虑所有注意事项,然后再次检查书写并尝试对其进行改进。相信它确实有效,因此,如果您以正确的方式进行所有操作,则不必担心结果。
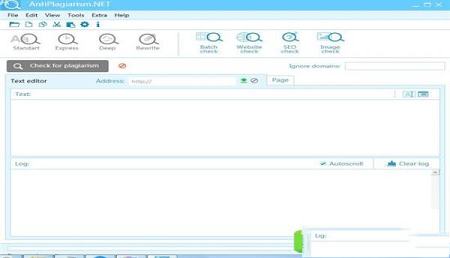
1、菜单
它包含用于应用程序设置和运行的所有必需命令。
2、工具栏
菜单中最常用的命令仅在此处重复。
3、文本编辑器
文本编辑器由一个窗口组成,可检查的文本粘贴到该窗口中并在其中进行编辑。
可检查文本有多种来源:
剪贴板中的文本:使用命令Edit/Paste或借助以下命令将复制的文本粘贴到文本编辑器窗口中热键组合。
文本或Word文档文件(*.txt,*。doc,*。docx,*。pdf,*。odt):借助“文件/打开文件”命令将文件的文本粘贴到编辑器窗口中。
来自Internet的Web文档:将页面URL粘贴到“地址”字段中,然后或选择“下载页面的html代码”(右键)以将初始文档代码下载到文本编辑器窗口中。同时,下载完成后,文本编辑器会自动切换到“页面”模式。
在文本编辑器中,提供了两种模式:
'页面'-文本被检测为与浏览器中一样显示的html文档文本。在这种模式下,无法进行编辑。
'文本编辑器'-允许文本编辑。
另外,编辑器能够在单独的窗口中的文本编辑器的右侧显示所谓的规范化文本。一个规范化的文本是原文与所有奇数空格,标点符号,HTML的标记和不同不相干的话删除。对于两个文档的比较,以下是它们的规范化变体。这些默认变量不会显示,但是可以在需要时通过菜单启用显示功能(“查看/显示规范化文本”)。
检查完成后,找到的原始文本片段将以不同的颜色突出显示(特定匹配颜色与原始颜色之间的对应关系显示在日志中)。如果在多个来源中找到任何文本片段,则该片段以黄色突出显示。
4、页
页面代表集成的浏览器窗口。
在检查过程中,将记录“在YYY找到XXX%匹配项”之类的消息。
通过单击链接YYY,位于给定地址的文档将显示在页面选项卡上,原始可检查文本的一致片段用黄色标记突出显示。
5、日志
在本节中,检查结果以实时模式记录。它还包含诊断消息和错误消息。
默认的详细日志记录已禁用,但可以在程序设置中(工具/首选项/报告/在Log中显示有关检查进度的详细信息)在需要时启用它。
二、首选项
1、通用设置
程序运行原理:
创建来自可检查文本的单词样本以用作搜索查询文本(单词的样本大小和样本数在“基本参数 ” 中指定)。
建立查询(搜索引擎一个接一个地使用,它们在“基本参数”中指定)。
分析搜索引擎的响应,并从中获取指向Web文档的链接。仅选择与搜索引擎最相关的链接,即仅选择头查询(“ 基本参数”中指定了从每个搜索引擎响应中获取的样本的链接数)。
这些参考文献下载了页面。
可检查文本与已还原副本片段匹配的百分比是通过带状疱疹方法确定的(带状疱疹中的单词数在“ 抄袭检测/带状疱疹中的单词”中指定)。
检测在下载页面上找到的匹配项的总百分比。
“更改常规设置”包含基本参数中的许多设置参数,例如Default,Express,Deep。已保存包含用户保存的基本参数中的最新参数集。
在“ 检查抄袭”操作期间,“ 已保存”中的参数集将用作“ 基本参数”中的设置。
选项抄袭检测/抄袭限制(%)指定原始可检查文本与在检查操作期间下载的每个页面之间的匹配项的最大允许百分比。如果超过此限制,搜索操作将自动停止。默认抄袭限制为50%。
2、网络
如果没有直接连接到Internet,则此选项卡允许配置代理设置。
注意:请注意,在这种情况下,代理列表不能用作自动搜索保护工具(“首选项” /“其他” /“自动搜索保护” /“使用http-代理列表”)
3、报告
自动保存指定每次搜索操作后要自动保存在程序根目录下“自动保存”文件夹中的最近报告的数量。根据给定操作完成的时间对报告进行授权。菜单项File / Autosaves提供对它们的快速访问。
历史记录指定要保存的最近搜索操作的数量。它会影响“日志”中任何检查操作结果的可用性。
日志允许详细记录检查进度。此默认选项已禁用。
4、下载
使用替代下载模式允许在检查过程中使用其他内页下载机制。
注意:如果使用该程序下载页面时遇到任何问题,请使用此模式(例如,如果连续出现错误“无法加载页面...”)。在“ 网站检查 ” 期间在网站上形成页面列表时使用相同的模式。
5、例外
它指定了一组在检查文本是否抄袭时将被忽略的URL地址/域。
如果可测试文档文本是来自Internet的Web文档,则忽略与检查网站或html-page相同域中的页面很有用。例如,要检查的文本是通过“ 地址 ”字段(未在文本编辑器中编辑的)粘贴到“ 文本编辑器 ”中的,或者如果页面检查是通过“ 网站检查 ”进行的。参数' 域级别'确定可检查页面/站点地址中的顶级域,在检查操作期间,所有子域都将忽略该顶级域。默认域级别为2。这意味着在检查站点//www.site.com页面(例如//site.com/page.html、//www.site.com/)时page.html,http://sub3.site.com/page.html、http://sub4.sub3.site.com/page.html、http://sub5.sub4.sub3.site.com/page。 html将被忽略。
忽略文件中的地址允许在检查操作期间指定要忽略的某些地址。通用文本文件(txt。)包含一组地址,每个地址都换行。
以下是此类文件的示例:
//www.ignoreurl1.com
//www.ignoreurl2.com/index.html
//www.ignoreurl2.ru/page3.html
通过忽略文件中的域,可以指定在检查过程中忽略的整个域。通用文本文件(txt。)包含一组域,每个域都换行。
这样的文件内容的示例如下所示:
//subdomen1.domen1.com
domen2.org
//domen3.ru/
三、批量检查/网站检查
在程序中,除了常规检查外,还有两个选项:批处理检查,即从指定目录中检查文档,以及网站检查,即从指定地址获取地址的网站或单独页面。文本文件。
1、批量检查
当获取所有文本和Word文档(* .txt,*。doc,*。docx,*。pdf,*。odt)但其数量受集合'限制时,这是对指定目录中文档的检查。最大文件数 '。默认代码是自动指定的,但也可以从包含代码的弹出列表中进行手动设置。
2、网站检查
检查操作分为几个步骤:
对于站点检查,首先需要下载其页面,方法是在“输入地址”字段中设置其地址,然后选择“下载”按钮,或者按下“ 从文件加载 ”按钮,然后选择带有地址列表的文本文件(每个地址都放在单独的行上)。
注意:在下载之前,可以指定下载过滤器,以消除不合适的Web文档。
在包含下载页面的窗口中,有一个选择列,允许在此步骤从清单中排除任何页面。
3、检查操作启动本身
注意:显示过滤器“ 禁止”显示由于下载过滤器或地址位于robot.txt文件(通常位于网站根目录)中而未下载的页面。
2、准确确定文本唯一性的百分比
3、在还原的网页副本上直接找到并突出显示非唯一的文本片段
4、С进行整个文件文件夹的批量搜索
5、检查网页的唯一性
6、查找与存储的搜索引擎副本匹配的项
7、使用代理列表等
8、多种格式支持:doc,docx,pdf,odt,html,txt,rtf。
9、预定义的检查首选项集(默认,快速,深层)。
10、批量检查。
11、网站检查。
12、高级首选项。
13、简单的界面。
14、通过用不同的颜色标记来显示非唯一短语。
安装破解教程
1、在本站下载并解压,得到Setup.exe安装程序和cracked破解文件夹2、双击Setup.exe运行,选择软件安装路径,点击next
3、安装完成,点击finish
4、将cracked中的Antiplagiarism.exe复制到安装目录中,点击替换目标中的文件
功能介绍
1、在最大的搜索引擎的索引中搜索窃(包括已保存的页面副本)2、用百分比定义所谓的文本唯一性
3、在观察的文本和源网页的重新创建副本中突出显示重复的片段 编辑 页
4、发现肮脏的唯一性制作方法–这些方法包括用其他语言的相同字母替换字母,插入隐藏的utf符号
5、各种各样的搜索条件设置–样本大小,带状疱疹中的单词数等
6、预定义设置–“默认”,“快速”,“深度” 首选项-一般
7、定义URL页面和整个域的可能性,在检查过程中将被忽略 首选项-例外
8、手动输入或自动识别(通过API防盗门)搜索引擎验证码
9、使用代理列表(最大程度减少被搜索引擎阻止的可能性) 首选项-其他
10、保存检查结果的详细报告
.doc,.docx,.pdf,.odt,.html,.txt,.rtf-格式支持
11、简单直观的界面
12、“网站检查” –检查网站页面是否存在抄袭(您也可以在文本文件中指定地址列表) 网站检查
13、“批处理检查” –检查给定文件夹中的多个文件 批量检查
14、“本地检查” –从Windows OS索引的本地目录中检查文档是否存在抄袭 本地检查
15、“图像检查” –检查照片是否重复 图像检查
16、“文本比较” –定义两个文本之间的相似性 文字比较
17、“ Seo服务” –定义地址/域的SEO分析:检测Google Pr,Yandex TIC,Google和Yandex索引的页面数,在Yandex目录中的存在,DMOZ等) Seo服务
使用说明
1、了解有关使用抄袭检查程序的所有信息每年,越来越多的大学对项目和论文的原始文本提出更高的要求。此外,令人惊讶的是,不仅学生,而且还有太多的老师仍然不了解作品的原创性意味着什么。然而,学术诚信要求写作具有100%的新颖性,如今很难不让所有这些可用信息迷失。作者应注意不正确的引用,措辞和其他类似操作,以免得到可怕的结果。
2、学生抄袭检查器
在这种情况下,最好的解决方案是使用a窃检查器。它可以轻松地帮助用户省略工作中的相似部分,并消除所有可能的错误。除此以外,抄袭检测器是提高写作水平的绝好机会,它的构想新颖,结论精妙,因此更加有趣。为学生提供的抄袭软件可以保证获得百分百的成绩。否则,您可能会冒无法通过课程的风险,甚至会失去出色的职业机会。您最好尝试该程序并立即改善工作,而不要靠运气而错过成功的未来机会。
3、如何在线使用Pla窃检查器
独创性检查器的最佳功能是它可以24/7在线运行。这意味着您无需外出就可以找到出色的助手来撰写高质量的作品。在这里,您可以无限制地检查作业,然后老师才能对其进行检查。首先,这并不难。您只需要复制粘贴信息,然后单击“检查此文本”按钮即可。然后,该软件开始浏览各种资源以比较信息,因此您必须等待几秒钟。之后,程序将报告可能的窃事件,并突出显示它们。最后,您必须考虑所有注意事项,然后再次检查书写并尝试对其进行改进。相信它确实有效,因此,如果您以正确的方式进行所有操作,则不必担心结果。
使用帮助
一、程序界面1、菜单
它包含用于应用程序设置和运行的所有必需命令。
2、工具栏
菜单中最常用的命令仅在此处重复。
3、文本编辑器
文本编辑器由一个窗口组成,可检查的文本粘贴到该窗口中并在其中进行编辑。
可检查文本有多种来源:
剪贴板中的文本:使用命令Edit/Paste或借助以下命令将复制的文本粘贴到文本编辑器窗口中热键组合。
文本或Word文档文件(*.txt,*。doc,*。docx,*。pdf,*。odt):借助“文件/打开文件”命令将文件的文本粘贴到编辑器窗口中。
来自Internet的Web文档:将页面URL粘贴到“地址”字段中,然后或选择“下载页面的html代码”(右键)以将初始文档代码下载到文本编辑器窗口中。同时,下载完成后,文本编辑器会自动切换到“页面”模式。
在文本编辑器中,提供了两种模式:
'页面'-文本被检测为与浏览器中一样显示的html文档文本。在这种模式下,无法进行编辑。
'文本编辑器'-允许文本编辑。
另外,编辑器能够在单独的窗口中的文本编辑器的右侧显示所谓的规范化文本。一个规范化的文本是原文与所有奇数空格,标点符号,HTML的标记和不同不相干的话删除。对于两个文档的比较,以下是它们的规范化变体。这些默认变量不会显示,但是可以在需要时通过菜单启用显示功能(“查看/显示规范化文本”)。
检查完成后,找到的原始文本片段将以不同的颜色突出显示(特定匹配颜色与原始颜色之间的对应关系显示在日志中)。如果在多个来源中找到任何文本片段,则该片段以黄色突出显示。
4、页
页面代表集成的浏览器窗口。
在检查过程中,将记录“在YYY找到XXX%匹配项”之类的消息。
通过单击链接YYY,位于给定地址的文档将显示在页面选项卡上,原始可检查文本的一致片段用黄色标记突出显示。
5、日志
在本节中,检查结果以实时模式记录。它还包含诊断消息和错误消息。
默认的详细日志记录已禁用,但可以在程序设置中(工具/首选项/报告/在Log中显示有关检查进度的详细信息)在需要时启用它。
二、首选项
1、通用设置
程序运行原理:
创建来自可检查文本的单词样本以用作搜索查询文本(单词的样本大小和样本数在“基本参数 ” 中指定)。
建立查询(搜索引擎一个接一个地使用,它们在“基本参数”中指定)。
分析搜索引擎的响应,并从中获取指向Web文档的链接。仅选择与搜索引擎最相关的链接,即仅选择头查询(“ 基本参数”中指定了从每个搜索引擎响应中获取的样本的链接数)。
这些参考文献下载了页面。
可检查文本与已还原副本片段匹配的百分比是通过带状疱疹方法确定的(带状疱疹中的单词数在“ 抄袭检测/带状疱疹中的单词”中指定)。
检测在下载页面上找到的匹配项的总百分比。
“更改常规设置”包含基本参数中的许多设置参数,例如Default,Express,Deep。已保存包含用户保存的基本参数中的最新参数集。
在“ 检查抄袭”操作期间,“ 已保存”中的参数集将用作“ 基本参数”中的设置。
选项抄袭检测/抄袭限制(%)指定原始可检查文本与在检查操作期间下载的每个页面之间的匹配项的最大允许百分比。如果超过此限制,搜索操作将自动停止。默认抄袭限制为50%。
2、网络
如果没有直接连接到Internet,则此选项卡允许配置代理设置。
注意:请注意,在这种情况下,代理列表不能用作自动搜索保护工具(“首选项” /“其他” /“自动搜索保护” /“使用http-代理列表”)
3、报告
自动保存指定每次搜索操作后要自动保存在程序根目录下“自动保存”文件夹中的最近报告的数量。根据给定操作完成的时间对报告进行授权。菜单项File / Autosaves提供对它们的快速访问。
历史记录指定要保存的最近搜索操作的数量。它会影响“日志”中任何检查操作结果的可用性。
日志允许详细记录检查进度。此默认选项已禁用。
4、下载
使用替代下载模式允许在检查过程中使用其他内页下载机制。
注意:如果使用该程序下载页面时遇到任何问题,请使用此模式(例如,如果连续出现错误“无法加载页面...”)。在“ 网站检查 ” 期间在网站上形成页面列表时使用相同的模式。
5、例外
它指定了一组在检查文本是否抄袭时将被忽略的URL地址/域。
如果可测试文档文本是来自Internet的Web文档,则忽略与检查网站或html-page相同域中的页面很有用。例如,要检查的文本是通过“ 地址 ”字段(未在文本编辑器中编辑的)粘贴到“ 文本编辑器 ”中的,或者如果页面检查是通过“ 网站检查 ”进行的。参数' 域级别'确定可检查页面/站点地址中的顶级域,在检查操作期间,所有子域都将忽略该顶级域。默认域级别为2。这意味着在检查站点//www.site.com页面(例如//site.com/page.html、//www.site.com/)时page.html,http://sub3.site.com/page.html、http://sub4.sub3.site.com/page.html、http://sub5.sub4.sub3.site.com/page。 html将被忽略。
忽略文件中的地址允许在检查操作期间指定要忽略的某些地址。通用文本文件(txt。)包含一组地址,每个地址都换行。
以下是此类文件的示例:
//www.ignoreurl1.com
//www.ignoreurl2.com/index.html
//www.ignoreurl2.ru/page3.html
通过忽略文件中的域,可以指定在检查过程中忽略的整个域。通用文本文件(txt。)包含一组域,每个域都换行。
这样的文件内容的示例如下所示:
//subdomen1.domen1.com
domen2.org
//domen3.ru/
三、批量检查/网站检查
在程序中,除了常规检查外,还有两个选项:批处理检查,即从指定目录中检查文档,以及网站检查,即从指定地址获取地址的网站或单独页面。文本文件。
1、批量检查
当获取所有文本和Word文档(* .txt,*。doc,*。docx,*。pdf,*。odt)但其数量受集合'限制时,这是对指定目录中文档的检查。最大文件数 '。默认代码是自动指定的,但也可以从包含代码的弹出列表中进行手动设置。
2、网站检查
检查操作分为几个步骤:
对于站点检查,首先需要下载其页面,方法是在“输入地址”字段中设置其地址,然后选择“下载”按钮,或者按下“ 从文件加载 ”按钮,然后选择带有地址列表的文本文件(每个地址都放在单独的行上)。
注意:在下载之前,可以指定下载过滤器,以消除不合适的Web文档。
在包含下载页面的窗口中,有一个选择列,允许在此步骤从清单中排除任何页面。
3、检查操作启动本身
注意:显示过滤器“ 禁止”显示由于下载过滤器或地址位于robot.txt文件(通常位于网站根目录)中而未下载的页面。
软件亮点
1、已检查的文档不会离开您的计算机。该应用程序使用Google,Bing和其他搜索引擎。2、准确确定文本唯一性的百分比
3、在还原的网页副本上直接找到并突出显示非唯一的文本片段
4、С进行整个文件文件夹的批量搜索
5、检查网页的唯一性
6、查找与存储的搜索引擎副本匹配的项
7、使用代理列表等
8、多种格式支持:doc,docx,pdf,odt,html,txt,rtf。
9、预定义的检查首选项集(默认,快速,深层)。
10、批量检查。
11、网站检查。
12、高级首选项。
13、简单的界面。
14、通过用不同的颜色标记来显示非唯一短语。
∨ 展开
 VX Search(文件搜索工具)v12.8.14官方版
VX Search(文件搜索工具)v12.8.14官方版 天若OCR文字识别v4.46免安装便携版
天若OCR文字识别v4.46免安装便携版 天若OCR文字识别软件v5.0绿色电脑版
天若OCR文字识别软件v5.0绿色电脑版 Top Excel Password Recoveryv2.3破解版
Top Excel Password Recoveryv2.3破解版
 联盛UT163量产工具(MDPT)v3.9.8.0免费版
联盛UT163量产工具(MDPT)v3.9.8.0免费版
 MyDockv5.2.5 免费绿版
MyDockv5.2.5 免费绿版
 WPS 2019 珠海市政府专业版(含VBA) V11.8.2.8506 免激活版
WPS 2019 珠海市政府专业版(含VBA) V11.8.2.8506 免激活版
 xilisoft photo dvd maker中文版 V2.28 电脑版
xilisoft photo dvd maker中文版 V2.28 电脑版
 Firetrust MailWasher(垃圾邮件过滤清理软件) V7.12 官方版
Firetrust MailWasher(垃圾邮件过滤清理软件) V7.12 官方版
 Topaz Gigapixel AI破解版 V7.1.2 绿色便携版
Topaz Gigapixel AI破解版 V7.1.2 绿色便携版
 3Ds Max 2023极速翱翔精简版 中文免费版
3Ds Max 2023极速翱翔精简版 中文免费版
 magnetx(磁力猫bt下载链接) V3.1.7 官方最新版
magnetx(磁力猫bt下载链接) V3.1.7 官方最新版
 33搜帧软件下载 V0.10 免费版
33搜帧软件下载 V0.10 免费版
 番号搜索器v5.9绿色版
番号搜索器v5.9绿色版
 Search and Replacev8.3中文绿色破解版(已注册)
Search and Replacev8.3中文绿色破解版(已注册)
 萝莉云播放器v5.94最新版
萝莉云播放器v5.94最新版
 MagnetSearchv2.12绿色中文版
MagnetSearchv2.12绿色中文版
 WeChatDownload(微信公众号文章下载器)V3.262
WeChatDownload(微信公众号文章下载器)V3.262