
so-vits-svc4.0模型是一款非常有意思的AI模型软件,有了这款软件,大家只需要输入歌曲的歌词和曲调,就可以让它自动生成一首唱腔完美的歌曲,从而实现对歌曲的自主创作和演唱,如果你的声音数据足够强大的话,那么就能够模拟出不同歌手的声音,并且可以在不同音域和曲调下进行演唱。
【使用教程】
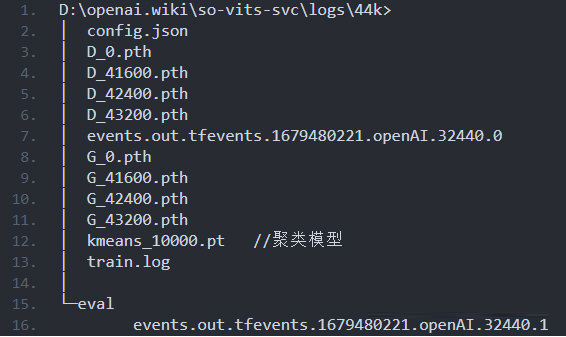
如果您想训练自己的声音模型并加以使用,需要以后几个步骤。
提取干音
音频切分
预处理
训练模型
配置模型
推理预测
【特别说明】
为避免可能的法律纠纷和道德风险,使用者在使用该整合包前,请务必仔细阅读本条款,继续使用即代表理解并同意该声明,如有异议,请立即停止使用并删除本整合包。
1、本整合包修改自So-VITS-SVC 4.0项目,该项目目前由So-VITS社区维护。
2、在使用本整合包时,必须根据知情同意原则取得数据集音声来源的授权许可,并根据授权协议条款规定使用数据集。
3、禁止使用该整合包对公众人物、政治人物或其他容易引起争议的人物进行模型训练。使用本整合包产出和传输的信息需符合中国法律、国际公约的规定、符合公序良俗。不将本整合包以及与之相关的服务用作非法用途以及非正当用途。
4、禁止将本整合包用于血腥、暴力、性相关、或侵犯他人合法权利的用途。
5、任何发布到视频平台的基于So-VITS制作的视频,都必须要在简介明确指明用于变声器转换的输入源歌声、音频,例如:使用他人发布的视频/音频,通过分离的人声作为输入源进行转换的,必须要给出明确的原视频、音乐链接;若使用是自己的人声,或是使用其他歌声合成引擎合成的声音作为输入源进行转换的,也必须在简介加以说明。

∨ 展开
 FL Studio 21中文破解版 v21.3.2304
FL Studio 21中文破解版 v21.3.2304







 Root大师v1.8.9.21144官方版
Root大师v1.8.9.21144官方版
 onedrivev20.169.0823.0008电脑版
onedrivev20.169.0823.0008电脑版
 太阳花浏览器v7.0.43.0官方版
太阳花浏览器v7.0.43.0官方版
 AutoCAD2006注册机32/64位通用版
AutoCAD2006注册机32/64位通用版
 极品飞车16亡命狂飙中文版豪华破解版(附修改器)
极品飞车16亡命狂飙中文版豪华破解版(附修改器)
 Animizv2.5.6绿色版
Animizv2.5.6绿色版
 丁香医考v6.1.1电脑版
丁香医考v6.1.1电脑版
 网易UU远程 V0.1.5.340 官方最新版
网易UU远程 V0.1.5.340 官方最新版
 NaturalReader 16v16.1.2破解版
NaturalReader 16v16.1.2破解版
 QVE人声分离v1.0.4破解版
QVE人声分离v1.0.4破解版
 Studio One 6中文破解版 V6.0.2 最新免费版
Studio One 6中文破解版 V6.0.2 最新免费版
 Adobe Audition CCv6.0.732绿色免注册破解版
Adobe Audition CCv6.0.732绿色免注册破解版
 录音啦v5.2免安装绿色破解版
录音啦v5.2免安装绿色破解版
 元气音频变声器 V1.0 免费版
元气音频变声器 V1.0 免费版
 AutoTune pro 9v9.10破解版
AutoTune pro 9v9.10破解版