
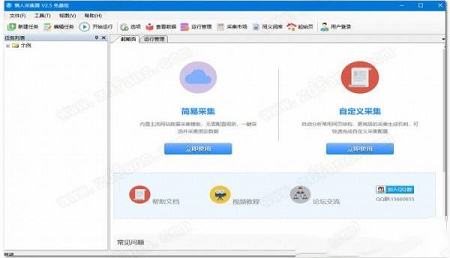
懒人采集器是一款专业的网页页面信息采集工具。软件主要应用于页面信息的快速简易采集,以及用户自己选择所需要的文件类型与格式,而后软件自动分析当前网页页面的结构,并进行专业的筛选,按照用户需求精准的摘选出您想要的文件以及文字信息。用户在使用本软件时不需要编辑程序,只要选择好自己所需要的文件类型以及关键词,软件就可以自动生成高级的采集机制,帮助您准确无误的抓取您想要的内容,而且简易的页面采集创建功能,可以更好的帮助用户使用该软件,更加快捷的寻找出自己所想要的文件位置,强大的可视化配置让您对软件的运行以及当前状况了如指掌,方便的使用软件中的各个功能。软件可以自动识别网页中的页面列表,并智能识别页面中的采集字段以及分页,并支持多个数据信息采集引擎的同时运行,用户还可以在软件内设置网页信息的采集时间段,到达时间段后,软件会自动采集该页面中的数据信息,全自动运行无需人工操作,大大提升了您的效率以及时间,节省了人工的成本,软件内的自动拦截功能,可以在软件运行采集过程中可以自动屏蔽页面内的广告,帮助用户更好的进行网页数据的采集。本软件适应全网99%的网站页面,而且对于不懂的如何进行数据采集以及网络技术的用户来说,只需要进行上网选择相应的页面就可以了,门槛极低。小编强烈推荐本款懒人采集器官方版,感兴趣的朋友们,快来下载吧。
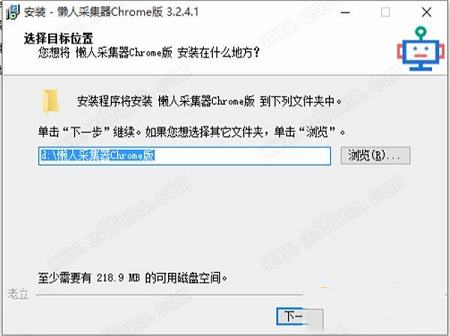
2、选择安装位置;
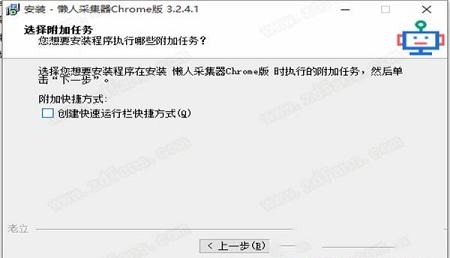
3、选择附加任务;
4、准备安装;
5、安装完成;

2、多引擎,高速稳定:内置高速浏览器引擎,还可以切换为HTTP引擎模式运行,采集数据更加高效。还内置了JSON引擎,无需分析JSON数据结构,可视化选取JSON内容;
3、适用各种网站 :能够采集互联网99%的网站,包括单页应用Ajax加载等等动态类型网站。
2、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,加上独创的内存优化使浏览器采集也可以高速运行,甚至可以快速转换为HTTP方式运行,享受更高的采集速度;
3、而在抓取JSON数据时,同样可以使用浏览器可视化方式,通过鼠标点选需要抓取的内容,完全不需要去分析JSON数据结构,使非网页专业设计人士也可以轻松抓取需要的数据;
4、不用分析网页请求和源代码,却支持更多的网页采集;
5、先进的智能算法,可以一键生成目标元素XPATH、自动识别网页列表、自动识别分页中的下一页按钮;
6、支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件;
7、也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,通过向导的方式简单映射字段,即可轻松导出到目标网站数据库中。
2、计划任务:灵活定义运行时间,全自动运行;
3、多引擎支持:支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎;
4、智能识别:可自动识别网页列表、采集字段和分页等;
5、拦截请求:自定义拦截域名,方便过滤站外广告,提高采集速度;
6、多种数据导出:可导出为Txt 、Excel、MySQL、SQLServer、 SQlite、Access、网站等。
2、优化规则编辑器线程及网页加载判断问题;
3、修复个别规则最小化运行出错问题;
4、改进软件编译加密方式;
5、其他一些细节改进。
安装教程
1、解压下载文件,打开软件;2、选择安装位置;
3、选择附加任务;
4、准备安装;
5、安装完成;
软件功能
1、零门槛:不懂网络爬虫技术,会上网,懒人采集器就会采集网站数据;2、多引擎,高速稳定:内置高速浏览器引擎,还可以切换为HTTP引擎模式运行,采集数据更加高效。还内置了JSON引擎,无需分析JSON数据结构,可视化选取JSON内容;
3、适用各种网站 :能够采集互联网99%的网站,包括单页应用Ajax加载等等动态类型网站。
软件特色
1、懒人采集器操作简单,可通过鼠标点击的方式轻松选取要抓取的内容;2、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,加上独创的内存优化使浏览器采集也可以高速运行,甚至可以快速转换为HTTP方式运行,享受更高的采集速度;
3、而在抓取JSON数据时,同样可以使用浏览器可视化方式,通过鼠标点选需要抓取的内容,完全不需要去分析JSON数据结构,使非网页专业设计人士也可以轻松抓取需要的数据;
4、不用分析网页请求和源代码,却支持更多的网页采集;
5、先进的智能算法,可以一键生成目标元素XPATH、自动识别网页列表、自动识别分页中的下一页按钮;
6、支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件;
7、也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,通过向导的方式简单映射字段,即可轻松导出到目标网站数据库中。
软件亮点
1、可视化向导:所有采集元素,自动生成采集数据;2、计划任务:灵活定义运行时间,全自动运行;
3、多引擎支持:支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎;
4、智能识别:可自动识别网页列表、采集字段和分页等;
5、拦截请求:自定义拦截域名,方便过滤站外广告,提高采集速度;
6、多种数据导出:可导出为Txt 、Excel、MySQL、SQLServer、 SQlite、Access、网站等。
更新日志
1、新增网页加载延迟选项;2、优化规则编辑器线程及网页加载判断问题;
3、修复个别规则最小化运行出错问题;
4、改进软件编译加密方式;
5、其他一些细节改进。
∨ 展开
 谷歌访问助手v2.3.0破解版
谷歌访问助手v2.3.0破解版 Tampermonkey油猴v4.8官方版
Tampermonkey油猴v4.8官方版 Artweaver Plusv7.0.4中文绿色版
Artweaver Plusv7.0.4中文绿色版
 红白机模拟器v2.6中文版
红白机模拟器v2.6中文版
 WYSIWYG Web Builder(网页模板设计工具)v15.0.6破解版(附注册信息)
WYSIWYG Web Builder(网页模板设计工具)v15.0.6破解版(附注册信息)
 Camtasia Studio 9汉化补丁v9.1.5.16
Camtasia Studio 9汉化补丁v9.1.5.16
 SoSo工具集v9.0最新版
SoSo工具集v9.0最新版
 不思议的皇冠v0.2.1.3破解版
不思议的皇冠v0.2.1.3破解版
 Corel PaintShop Pro2023破解版 V25.1 免费版
Corel PaintShop Pro2023破解版 V25.1 免费版
 mptrim中文版 V3.0.2 汉化破解版
mptrim中文版 V3.0.2 汉化破解版
 360极速浏览器绿色精简优化版 V13.5.1060.0 吾爱破解版
360极速浏览器绿色精简优化版 V13.5.1060.0 吾爱破解版
 企微宝v2.6.4破解版
企微宝v2.6.4破解版
 Big JPG(AI人工智能图片放大的在线工具)v1.0免安装便携版
Big JPG(AI人工智能图片放大的在线工具)v1.0免安装便携版
 迷你派采集器(Chrome网页采集器插件)v1.0.35免费版
迷你派采集器(Chrome网页采集器插件)v1.0.35免费版
 HTTP Debugger Pro特别破解版v9.0.3
HTTP Debugger Pro特别破解版v9.0.3
 Stylus(Chrome网页样式管理器插件)v1.5.17免费版
Stylus(Chrome网页样式管理器插件)v1.5.17免费版