
kettle是一款用于数据库编辑的专业软件。它是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,数据抽取高效稳定。软件中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。它能够能帮助你轻松连接数据库的工具,本程序需要JAVA支持,要先安装JRE虚拟机后才能运行,同事软件内置创建数据库连接向导和复制拷贝表向导,小编这里给你带来的是绿色版,软件绿色无需安装。软件可以帮助你实现你的ETTL需要:抽取、转换、装入和加载数据数据,且抽取高效稳定。软件这个ETL工具集,翻译成中文名称应该叫水壶,寓意为希望把各种数据放到一个壶里然后以一种指定的格式流出。

2、配置软件的环境变量:(前提是配置好Java的环境变量,因为他是java编写,需要本地的JVM的运行环境)在系统的环境变量中添加KETTLE_HOME变量,目录指向软件的安装目录
新建系统变量:KETTLE_HOME
变量值: D:\kettle\data-integration(具体以安装路径为准,软件的解压路径,直到Kettle.exe所在目录)
选择PATH添加环境变量:
变量名:PATH
变量值:% KETTLE_HOME%;
3、建立转换。
在文件->新建装换。
新建转换后在左边的主对象树中建立DB连接用以连接数据库。
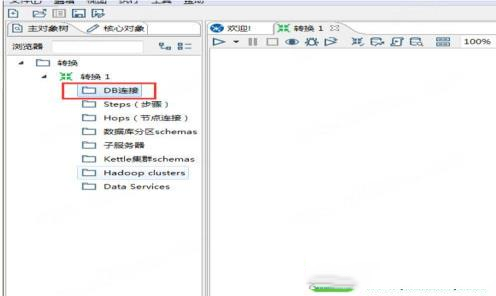
建立数据库连接的过程与其他数据库管理软件连接数据库类似。
注意:在数据库链接的过程中,可能会报某个数据库连接找不到的异常。那是因为你没有对应的数据库链接驱动,请下载对应驱动后,放入软件的lib文件夹。
4、简单的数据表插入\更新
新建表插入
在左边的面板中选择“核心对象”,在核心对象里面选择“输入->表输入”,用鼠标拖动到右边面板。
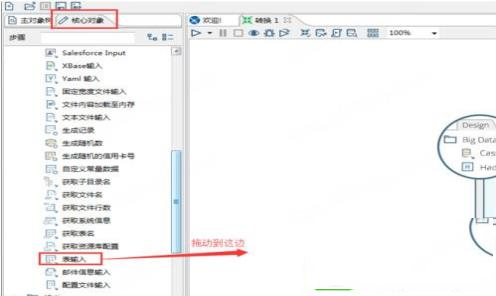
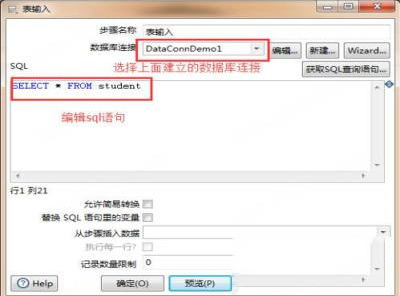
5、双击拖过来的表,可以编辑表输入。
选择数据库连接和编辑sql语句,在这一步可以点击预览,查看自己是否连接正确。
6、通过插入\更新输出到表。
在左边面板中选择核心对象、选择“输出->插入\更新”
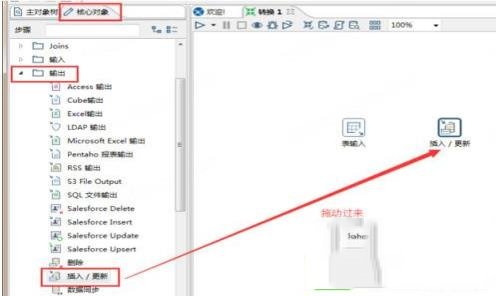
7、编辑插入更新:
首先:表输入连接插入更新。
选中表输入,按住shift键,拖向插入更新。
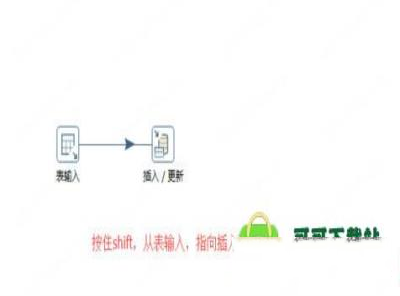
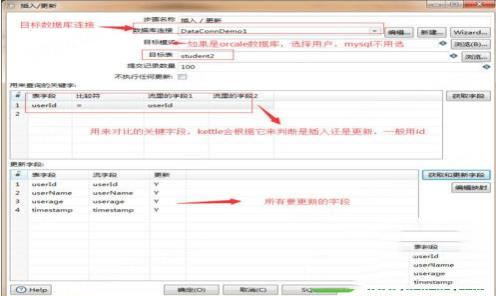
8、然后:双击插入更新,编辑它。
到这里基本上,这个转换就要做完了,可以点击运行查看效果,看是否有误,这个要先保存了才能运行,可以随意保存到任何一个地方。
9、使用作业控制上面装换执行。
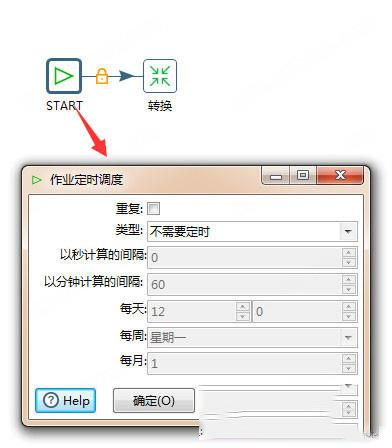
使用作业可以定时或周期性的执行转换,新建一个作业。并从左边面板拖入start 和转换。
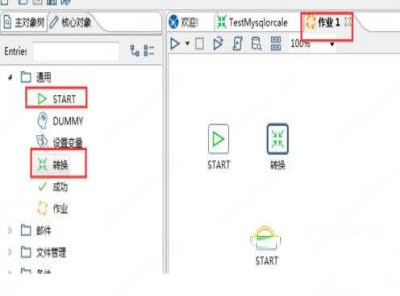
10、双击start可以编辑,可以设置执行时间等等
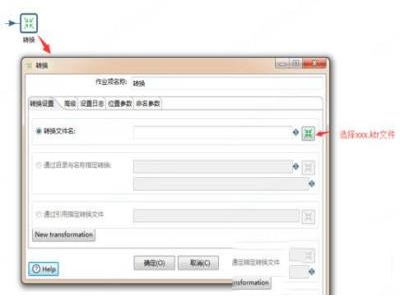
11、点开装换,可以设置需要执行的转换任务,比如可以执行上面我们做的转换,XXX.ktr最后点击运行即可。
作为一款开源的软件,拥有十分完善的功能特性
2、多端运行
可以在windows、mac、Linux等多个系统上运行
3、上手快速
使用图形界面,学习使用上手更加迅速,十分实用
4、高效运行
软件运行起来十分流畅高效,不卡顿,感受更好
5、性能稳定
kettle用于数据库的连接十分稳定可靠,可以放心使用
2、前置机模式:这是一种典型的数据交换应用场景,数据交换的双方A和B网络不通,但是A和B都可以和前置机C连接,一般的情况是双方约定好前置机的数据结构,这个结构跟A和B的数据结构基本上是不一致的,这样我们就需要把应用上的数据按照数据标准推送到前置机上,这个研发工作量还是比较大的;
3、文件模式: 数据交互的双方A和B是完全的物理隔离,这样就只能通过以文件的方式来进行数据交互了,例如XML格式,在应用A中我们开发一个接口用来生成标准格式的XML,然后用优盘或者别的介质在某一时间把XML数据拷贝之后,然后接入到应用B上,应用B上在按照标准接口解析相应的文件把数据接收过来
修改一下spoon.bat里内存配置:
if "%PENTAHO_DI_JAVA_OPTIONS%"=="" set PENTAHO_DI_JAVA_OPTIONS="-Xms2058m" "-Xmx1024m" "-XX:MaxPermSize=256m"
改为
if "%PENTAHO_DI_JAVA_OPTIONS%"=="" set PENTAHO_DI_JAVA_OPTIONS="-Xms512m" "-Xmx512m" "-XX:MaxPermSize=256m"
2、如何连接资源库?
如果没有则创建资源库
3、如何连接数据库?
在连接数据库之前,首先需要保证当前在一个transform(转换)页面,然后点击左侧选项栏中的“主对象树”,然后右键点击“DB连接”,选择“新建”。
当然也可以设置一些其他的连接属性,如zeroDateTimeBehavior=round&characterEncoding=utf8。
4、如何解决数据库连接更新不及时问题?
有时候我们数据库中的表的字段进行了更新(增加或删除字段),但是在使用“表输入”控件的“获取SQL语句”功能是会发现的到的字段还是原来的字段,这是由于缓存造成的,需要进行缓存清理。
5、如何解决Unable to read file错误?
有时候我们在文件夹中将Job或Transform移动到其他目录之后,执行时会出现Unable to read file错误。然后就进入到了当前Transform的配置页面。修改配置中的目录即可。
6、如何解决tinyint类型数据丢失问题?
在软件使用JDBC连接MySQL时,对于表中数据类型为tinyint的字段,读取时有可能会将其转为bool类型,这有可能造成数据丢失。例如,有一个叫status名字的tinyint类型字段,取值有三种:0、1、2。软件读取之后很可能将0转为false,1、2都转为true。输出时,将false转为0,true转为1,这样就会造成元数据中status为2的数据被错误的赋值为1。
解决这个问题时,可以在读取元数据时将status转为int或char。比如SELECT CAST(status as signed) as status FROM 或SELECT CAST(status as char) as status FROM
2、远程监控和执行转换
3、集群支持(MPP)
4、数据库分区支持(不与表划分混淆)
5、大量的内存和性能改进
6、增强的数据库支持
7、改进的报价算法
8、在步骤中分离架构/所有者和表名
9、数据库连接池支持

使用教程
1、打开Spoon.bat,打开后请耐心等待一会儿时间。2、配置软件的环境变量:(前提是配置好Java的环境变量,因为他是java编写,需要本地的JVM的运行环境)在系统的环境变量中添加KETTLE_HOME变量,目录指向软件的安装目录
新建系统变量:KETTLE_HOME
变量值: D:\kettle\data-integration(具体以安装路径为准,软件的解压路径,直到Kettle.exe所在目录)
选择PATH添加环境变量:
变量名:PATH
变量值:% KETTLE_HOME%;
3、建立转换。
在文件->新建装换。
新建转换后在左边的主对象树中建立DB连接用以连接数据库。
建立数据库连接的过程与其他数据库管理软件连接数据库类似。
注意:在数据库链接的过程中,可能会报某个数据库连接找不到的异常。那是因为你没有对应的数据库链接驱动,请下载对应驱动后,放入软件的lib文件夹。
4、简单的数据表插入\更新
新建表插入
在左边的面板中选择“核心对象”,在核心对象里面选择“输入->表输入”,用鼠标拖动到右边面板。
5、双击拖过来的表,可以编辑表输入。
选择数据库连接和编辑sql语句,在这一步可以点击预览,查看自己是否连接正确。
6、通过插入\更新输出到表。
在左边面板中选择核心对象、选择“输出->插入\更新”
7、编辑插入更新:
首先:表输入连接插入更新。
选中表输入,按住shift键,拖向插入更新。
8、然后:双击插入更新,编辑它。
到这里基本上,这个转换就要做完了,可以点击运行查看效果,看是否有误,这个要先保存了才能运行,可以随意保存到任何一个地方。
9、使用作业控制上面装换执行。
使用作业可以定时或周期性的执行转换,新建一个作业。并从左边面板拖入start 和转换。
10、双击start可以编辑,可以设置执行时间等等
11、点开装换,可以设置需要执行的转换任务,比如可以执行上面我们做的转换,XXX.ktr最后点击运行即可。
功能特色
1、开源实用作为一款开源的软件,拥有十分完善的功能特性
2、多端运行
可以在windows、mac、Linux等多个系统上运行
3、上手快速
使用图形界面,学习使用上手更加迅速,十分实用
4、高效运行
软件运行起来十分流畅高效,不卡顿,感受更好
5、性能稳定
kettle用于数据库的连接十分稳定可靠,可以放心使用
应用场景
1、表视图模式:这种情况我们经常遇到,就是在同一网络环境下,我们对各种数据源的表数据进行抽取、过滤、清洗等,例如历史数据同步、异构系统数据交互、数据对称发布或备份等都归属于这个模式;传统的实现方式一般都要进行研发(一小部分例如两个相同表结构的表之间的数据同步,如果sqlserver数据库可以通过发布/订阅实现),涉及到一些复杂的一些业务逻辑如果我们研发出来还容易出各种bug;2、前置机模式:这是一种典型的数据交换应用场景,数据交换的双方A和B网络不通,但是A和B都可以和前置机C连接,一般的情况是双方约定好前置机的数据结构,这个结构跟A和B的数据结构基本上是不一致的,这样我们就需要把应用上的数据按照数据标准推送到前置机上,这个研发工作量还是比较大的;
3、文件模式: 数据交互的双方A和B是完全的物理隔离,这样就只能通过以文件的方式来进行数据交互了,例如XML格式,在应用A中我们开发一个接口用来生成标准格式的XML,然后用优盘或者别的介质在某一时间把XML数据拷贝之后,然后接入到应用B上,应用B上在按照标准接口解析相应的文件把数据接收过来
常见问题
1、软件无法启动修改一下spoon.bat里内存配置:
if "%PENTAHO_DI_JAVA_OPTIONS%"=="" set PENTAHO_DI_JAVA_OPTIONS="-Xms2058m" "-Xmx1024m" "-XX:MaxPermSize=256m"
改为
if "%PENTAHO_DI_JAVA_OPTIONS%"=="" set PENTAHO_DI_JAVA_OPTIONS="-Xms512m" "-Xmx512m" "-XX:MaxPermSize=256m"
2、如何连接资源库?
如果没有则创建资源库
3、如何连接数据库?
在连接数据库之前,首先需要保证当前在一个transform(转换)页面,然后点击左侧选项栏中的“主对象树”,然后右键点击“DB连接”,选择“新建”。
当然也可以设置一些其他的连接属性,如zeroDateTimeBehavior=round&characterEncoding=utf8。
4、如何解决数据库连接更新不及时问题?
有时候我们数据库中的表的字段进行了更新(增加或删除字段),但是在使用“表输入”控件的“获取SQL语句”功能是会发现的到的字段还是原来的字段,这是由于缓存造成的,需要进行缓存清理。
5、如何解决Unable to read file错误?
有时候我们在文件夹中将Job或Transform移动到其他目录之后,执行时会出现Unable to read file错误。然后就进入到了当前Transform的配置页面。修改配置中的目录即可。
6、如何解决tinyint类型数据丢失问题?
在软件使用JDBC连接MySQL时,对于表中数据类型为tinyint的字段,读取时有可能会将其转为bool类型,这有可能造成数据丢失。例如,有一个叫status名字的tinyint类型字段,取值有三种:0、1、2。软件读取之后很可能将0转为false,1、2都转为true。输出时,将false转为0,true转为1,这样就会造成元数据中status为2的数据被错误的赋值为1。
解决这个问题时,可以在读取元数据时将status转为int或char。比如SELECT CAST(status as signed) as status FROM 或SELECT CAST(status as char) as status FROM
更新日志
1、新版kettle改进的性能和可扩展性2、远程监控和执行转换
3、集群支持(MPP)
4、数据库分区支持(不与表划分混淆)
5、大量的内存和性能改进
6、增强的数据库支持
7、改进的报价算法
8、在步骤中分离架构/所有者和表名
9、数据库连接池支持
∨ 展开
 Navicat Premium 12破解版中文(附破解补丁)
Navicat Premium 12破解版中文(附破解补丁) Unity Studiov0.6.6.0 绿色版
Unity Studiov0.6.6.0 绿色版
 翰宇餐饮管理系统 V10.1 官方版
翰宇餐饮管理系统 V10.1 官方版
 易达鞋厂订单管理软件 V36.0.01 官方版
易达鞋厂订单管理软件 V36.0.01 官方版
 ThunderShare PDF Password Remove(PDF密码移除工具) V3.6.8 官方版
ThunderShare PDF Password Remove(PDF密码移除工具) V3.6.8 官方版
 统治众神修改器 V1.0 MrAntiFun版
统治众神修改器 V1.0 MrAntiFun版
 SymbolCAD 2020A.08破解版(附破解补丁)
SymbolCAD 2020A.08破解版(附破解补丁)
 Tenorshare iCareFonev6.0.0.2中文破解版
Tenorshare iCareFonev6.0.0.2中文破解版
 莱莎的炼金工房3终结之炼金术士与秘密钥匙修改器 V1.0 一修大师版
莱莎的炼金工房3终结之炼金术士与秘密钥匙修改器 V1.0 一修大师版
 Navicat Premium 16破解版 v16.0.7(附安装教程)
Navicat Premium 16破解版 v16.0.7(附安装教程)
 Navicat for MySQL16中文破解版 V16.0.14 免注册码版
Navicat for MySQL16中文破解版 V16.0.14 免注册码版
 Navicat for PostgreSQL破解版v15.0.6(附破解教程)
Navicat for PostgreSQL破解版v15.0.6(附破解教程)
 PLSQL Developer 12中文破解版(附注册码机汉化补丁)
PLSQL Developer 12中文破解版(附注册码机汉化补丁)
 SQLyog 64位v12.09中文破解版
SQLyog 64位v12.09中文破解版
 Navicat 16 for SQLite破解版 V16.0.14 中文免费版
Navicat 16 for SQLite破解版 V16.0.14 中文免费版
 SQLite Expert Professionalv5.3.0.350完美破解版
SQLite Expert Professionalv5.3.0.350完美破解版