
万能文章采集器是一款方便易用的文章采集软件,其功能强大且完全免费使用。该软件操作简单,可以精确提取网页里的正文部分保存为文章,支持去标签、链接、邮箱等格式化处理,只需要短短的几分钟就可以采集你想要的任何文章。而且拥有独家首创智能的万能算法,可以只需输入关键字就能采集各种网页和新闻,还可以采集指定列表页(栏目页)的文章,精确提取网页里的正文部分保存为文章内容。同时还有插入关键词功能,可以识别标签或标点旁边插入,并且能识别英文空格间距插入,更有文章转译功能,也就是可以将文章从一种语言如中文转到另一种语言如英文或日文,再从英文或日文转回中文,这样就是一个转译周期,可以设定转译周期循环多次。如果您对某个关键词的文章感兴趣想进行批量性的下载,可以使用这款完全免费的水淼万能文章采集器,如需要的用户欢迎前来下载!
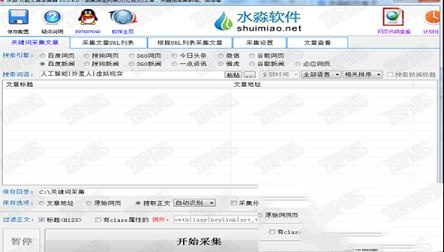
二、只需输入关键词,就能采集到百度新闻和网页、搜狗新闻和网页、360新闻和网页、谷歌新闻和网页、必应新闻和网页、雅虎;可批量关键词全自动采集。
三、可定向采集指定网站栏目列表下的所有文章,智能化匹配,无需编写复杂规则。
四、文章转译功能,可对采集好的文章,将其翻译到英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译。
五、史上最简单最智能文章采集器,支持全功能试用,效果如何一试就知!
此算法由水淼自主研发,可以在一个网页里提取出正文部分,通常精度可以达到95%,如果再进一步设置最少字数,采集的文章的精度(正确性)可以达到99%。同时文章标题也实现99%的提取精度。当然,一些网页排版格式比较混乱、不规则时,该精度可能有所下降。
正文提取模式
正文提取算法有3种模式,标准、严格、精确标签。大多数情况,标准和严格模式是相同的提取结果。下面说的是特殊情况:
标准模式:即一般性提取,大多数时候能够精确提取正文,但一些特殊页面会导致提取到一些不需要内容(但本模式能够较好识别类似百度经验的文章页面)
严格模式:顾名思义,比标准模式严格一点,可以很大程度避免不相关内容提取为正文,但对于特殊分段页面如百度经验的页面(不是一般
段落,而是有格式的多个独立div段),一般只能提取到某一段,而标准模式则可以提取全部段。
精确标签:当标准和严格模式不管用时,可以精确指定目标正文的标签头。本模式只适合网络批处理。
所以可以根据实际情况来切换模式。可以使用本地批处理的读网页正文功能来测试指定网页适合哪种模式提取。
采集时的处理选项
采集时可以同时进行转译、过滤、查词等处理。对于已采集好的文章可以使用《本地批处理》处理。
其中的转译功能,就是将中文翻译成英文再翻译回中文,也就产生了伪原创效果。支持原格式转译,也就是不改变文章原有标签结构、排版格式。
采集目标为网址
可以在网址模板里插入 #网址#、#标题#来组合引用
分页采集和相对路径转为绝对路径
打勾“自动采集分页”就能将分页文章采集合并,编辑框设置值为采集分页的最大数量。建议设置一个有限值如10页,避免一些分页过多的采集耗费时间长,合并后的文章体积大。如果需要采集全部分页,可以设置为0。
而文章里的所有相对路径都将自动转为绝对路径,如此可确保图片等正常显示。
多线程
支持多线程高速采集网页。可以根据网速而定,电信2m可以5个线程,电信4m可以10个线程,更多以此类推,但需适当设置,设置太多将可能严重影响采集效率甚至影响系统效率。如果采集时有其他占用流量的软件在运行比如在线视频播放,可以适当降低线程数。
文章标题和文章内容重复的处理
程序可以智能判断并过滤重复文章
当采集到的文章标题(文件名)与本地已经保存的文章标题相同时,水淼将首先判断两篇文章的相似度,当相似度大于 60% 时,水淼判断为相同文章,这时再比较两篇文章的文字多寡,自动使用文字多的文章覆盖写出到相同文件名处。这样的生成情况是不累加到生成数量的。
而当相似度低于 60% 时,水淼判断为不同文章,将自动重命名标题(取3到5个随机字母接在标题尾)保存到文件。
文章快速筛选器
虽然水淼研究了一个准确率极高的正文提取算法,但难免还是有极少数提取错误,这些错误主要是:目标网页的主体是在线视频,或主体内容过于简短而无法形成正文的特征。因此可以通过设置提取最终结果的字数多少来提高准确率(在“正文最少字数”参数,这个字数是程序将正文去标签、去行、去空格之后的纯文字字数)。
而文章快速筛选器就是为了快速查看采集好的文章,方便判断删除提取正文错误的文章。同时也方便基于网络信息采集目的而需要进行的炼选过程。
生成篇数不固定的问题
百度、搜搜默认每页100条结果,谷歌默认每页10条结果。
一些网站访问速度超时(尤其是谷歌收录的不少都是一些被墙的网站),或设置了正文最少字数,或程序忽略已在本地有同名的相似内容文章,或黑名单白名单的过滤等,都会造成实际生成篇数低于一页搜索最大结果数。
总体来说,百度采集的质量最好,生成篇数贴近搜索结果数。
2 软件同时支持32位64位运行环境;
3 如果软件无法正常打开,请右键使用管理员模式运行。
设置搜索间隔、采集类型、时间语言、排序方式、采集目标等参数
编辑网站的黑名单、白名单
设置转译选项、过滤选项、插词选项
点击“开始采集”按钮
软件特点
一、依托于水淼软件独家万能正文识别智能算法,可实现任何网页正文自动提取准确率95%以上。二、只需输入关键词,就能采集到百度新闻和网页、搜狗新闻和网页、360新闻和网页、谷歌新闻和网页、必应新闻和网页、雅虎;可批量关键词全自动采集。
三、可定向采集指定网站栏目列表下的所有文章,智能化匹配,无需编写复杂规则。
四、文章转译功能,可对采集好的文章,将其翻译到英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译。
五、史上最简单最智能文章采集器,支持全功能试用,效果如何一试就知!
功能介绍
什么是高精度正文识别算法此算法由水淼自主研发,可以在一个网页里提取出正文部分,通常精度可以达到95%,如果再进一步设置最少字数,采集的文章的精度(正确性)可以达到99%。同时文章标题也实现99%的提取精度。当然,一些网页排版格式比较混乱、不规则时,该精度可能有所下降。
正文提取模式
正文提取算法有3种模式,标准、严格、精确标签。大多数情况,标准和严格模式是相同的提取结果。下面说的是特殊情况:
标准模式:即一般性提取,大多数时候能够精确提取正文,但一些特殊页面会导致提取到一些不需要内容(但本模式能够较好识别类似百度经验的文章页面)
严格模式:顾名思义,比标准模式严格一点,可以很大程度避免不相关内容提取为正文,但对于特殊分段页面如百度经验的页面(不是一般
段落,而是有格式的多个独立div段),一般只能提取到某一段,而标准模式则可以提取全部段。
精确标签:当标准和严格模式不管用时,可以精确指定目标正文的标签头。本模式只适合网络批处理。
所以可以根据实际情况来切换模式。可以使用本地批处理的读网页正文功能来测试指定网页适合哪种模式提取。
采集时的处理选项
采集时可以同时进行转译、过滤、查词等处理。对于已采集好的文章可以使用《本地批处理》处理。
其中的转译功能,就是将中文翻译成英文再翻译回中文,也就产生了伪原创效果。支持原格式转译,也就是不改变文章原有标签结构、排版格式。
采集目标为网址
可以在网址模板里插入 #网址#、#标题#来组合引用
分页采集和相对路径转为绝对路径
打勾“自动采集分页”就能将分页文章采集合并,编辑框设置值为采集分页的最大数量。建议设置一个有限值如10页,避免一些分页过多的采集耗费时间长,合并后的文章体积大。如果需要采集全部分页,可以设置为0。
而文章里的所有相对路径都将自动转为绝对路径,如此可确保图片等正常显示。
多线程
支持多线程高速采集网页。可以根据网速而定,电信2m可以5个线程,电信4m可以10个线程,更多以此类推,但需适当设置,设置太多将可能严重影响采集效率甚至影响系统效率。如果采集时有其他占用流量的软件在运行比如在线视频播放,可以适当降低线程数。
文章标题和文章内容重复的处理
程序可以智能判断并过滤重复文章
当采集到的文章标题(文件名)与本地已经保存的文章标题相同时,水淼将首先判断两篇文章的相似度,当相似度大于 60% 时,水淼判断为相同文章,这时再比较两篇文章的文字多寡,自动使用文字多的文章覆盖写出到相同文件名处。这样的生成情况是不累加到生成数量的。
而当相似度低于 60% 时,水淼判断为不同文章,将自动重命名标题(取3到5个随机字母接在标题尾)保存到文件。
文章快速筛选器
虽然水淼研究了一个准确率极高的正文提取算法,但难免还是有极少数提取错误,这些错误主要是:目标网页的主体是在线视频,或主体内容过于简短而无法形成正文的特征。因此可以通过设置提取最终结果的字数多少来提高准确率(在“正文最少字数”参数,这个字数是程序将正文去标签、去行、去空格之后的纯文字字数)。
而文章快速筛选器就是为了快速查看采集好的文章,方便判断删除提取正文错误的文章。同时也方便基于网络信息采集目的而需要进行的炼选过程。
生成篇数不固定的问题
百度、搜搜默认每页100条结果,谷歌默认每页10条结果。
一些网站访问速度超时(尤其是谷歌收录的不少都是一些被墙的网站),或设置了正文最少字数,或程序忽略已在本地有同名的相似内容文章,或黑名单白名单的过滤等,都会造成实际生成篇数低于一页搜索最大结果数。
总体来说,百度采集的质量最好,生成篇数贴近搜索结果数。
使用说明
1 下载完成后不要在压缩包内运行软件直接使用,先解压;2 软件同时支持32位64位运行环境;
3 如果软件无法正常打开,请右键使用管理员模式运行。
使用方法
选择关键词设置搜索间隔、采集类型、时间语言、排序方式、采集目标等参数
编辑网站的黑名单、白名单
设置转译选项、过滤选项、插词选项
点击“开始采集”按钮
更新日志
新增对部分做了防采集处理的网站进行加强采集功能。∨ 展开
 Tampermonkey油猴v4.8官方版
Tampermonkey油猴v4.8官方版 谷歌访问助手v2.3.0破解版
谷歌访问助手v2.3.0破解版







 PicSizer(批量压缩图片软件) V4.9.3 中文版
PicSizer(批量压缩图片软件) V4.9.3 中文版
 SecureCRT(SSH终端仿真程序)x64注册机(含汉化补丁)
SecureCRT(SSH终端仿真程序)x64注册机(含汉化补丁)
 oCam(屏幕录像工具)v500.0中文免费版
oCam(屏幕录像工具)v500.0中文免费版
 Power Data Recovery(数据恢复软件)v9.0免费版
Power Data Recovery(数据恢复软件)v9.0免费版
 阿提拉全面战争十二项修改器 V1.0-V1.5.0 风灵月影版
阿提拉全面战争十二项修改器 V1.0-V1.5.0 风灵月影版
 ChessBase17破解版 V17.10 免费版
ChessBase17破解版 V17.10 免费版
 Opera浏览器v77.0.4054.172官方版
Opera浏览器v77.0.4054.172官方版
 鲁大师旧版5.0 V5.21.1300 老版本经典版
鲁大师旧版5.0 V5.21.1300 老版本经典版
 360极速浏览器绿色精简优化版 V13.5.1060.0 吾爱破解版
360极速浏览器绿色精简优化版 V13.5.1060.0 吾爱破解版
 企微宝v2.6.4破解版
企微宝v2.6.4破解版
 Big JPG(AI人工智能图片放大的在线工具)v1.0免安装便携版
Big JPG(AI人工智能图片放大的在线工具)v1.0免安装便携版
 迷你派采集器(Chrome网页采集器插件)v1.0.35免费版
迷你派采集器(Chrome网页采集器插件)v1.0.35免费版
 HTTP Debugger Pro特别破解版v9.0.3
HTTP Debugger Pro特别破解版v9.0.3
 Stylus(Chrome网页样式管理器插件)v1.5.17免费版
Stylus(Chrome网页样式管理器插件)v1.5.17免费版