
熊猫采集软件是一款非常优秀的网页数据采集工具,即使你不懂任何技术也可以轻松上手,发挥软件最大的功能,满足你对某方面信息的采集需求,功能强大且完全免费使用。该软件是新一代采集软件,全程可视化鼠标操作,用户无需关心网页源码,无需编写采集规则,无需使用正则表达式技术,全程智能化辅助,是采集软件行业的换代产品。同时也是通用性采集软件,可以应用在各个行业,满足各种采集需求(包括站群系统),是复杂采集需求的必选,也是采集软件使用新手的首选。它拥有强大的网页数据采集技术,可以帮助用户对网页上的图片、文本、视频等内容进行采集,还支持对成功抓取到的数据进行编辑,编辑后,可直接将其发布到自己的网站中,是一款非常简单易用的网页数据采集软件。利用熊猫精准搜索引擎的解析内核,实现对网页内容的仿浏览器解析,在此基础上利用原创的技术实现对网页框架内容与核心内容的分离、抽取,并实现相似页面的有效比对、匹配。因此,用户只需要指定一个参考页面,熊猫采集软件系统就可以据此来匹配类似的页面,来实现用户需要采集资料的批量采集。
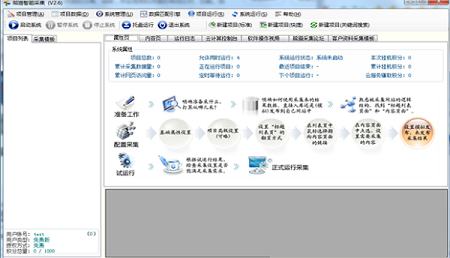
2.使用自己研发的解析引擎,实现对网页源码的仿浏览器解析
3.分解网页可视化内容元素,在此基础上进行机器学习、批量采集匹配
4.支持各种类型的分页模式
5.操作简单,不懂技术也可轻松操作
浏览器可见的内容都可以采集。采集的对象包括文字内容,图片,flash动画视频等等各类网络内容。支持图文混排对象的同时采集。
面向对象的采集方式
面向对象的采集方式。正文和回复内容同时采集的能力,分页的内容可轻松合并,采集内容可以是分散在多个页面内。结果可以是复杂的父子表结构。
采集速度快
熊猫采集的采集速度是采集软件中最快的(之一)。不使用落后低效的正则匹配技术。也不使用第三方内置浏览器访问的技术。使用自己研发的解析引擎。
结果数据完整度高
熊猫独有的多模板功能,确保结果数据完整不遗漏。独有的智能纠错模式,可以自动纠正模板和目标页面的不一致。
JS解析的自动判断识别
现在很多网页都采用了ajax网页内容动态生成技术。此时仅仅依靠网页源码,并不能获取需要的有效内容。此时就需要对被采集的页面执行JavaScript(JS)解析,获取JS执行后的结果代码。
熊猫支持对需要JS解析的页面,执行JS解析,获取JS解析后的实际内容。鉴于执行JS解析的速度效率很低,因此熊猫内置了智能判断功能,自动检查是否需要对被采集的页面执行JS解析,如果不需要的,尽量不使用低效的JS解析模式。
多模板自动适应能力
很多网站的“内容页面”会存在多个不同种类的模板,因此熊猫采集软件允许每个采集项目可以同时设置多个内容页面参考模板,在采集运行时,系统会自动匹配寻找最合适的参考模板用来分析内容页面。
实时帮助窗口
在采集项目设置环节,系统会在窗口右上显示与当前配置相关的实时帮助内容,为使用新手提供实时帮助。因此熊猫采集软件的使用可以轻松上手。配合全程智能化辅助能力,即便是第一次接触这款软件,也可以较轻松实现采集项目的配置工作。
分页内容的轻松合并
支持各种类型的分页模式,用户只需要做两步就可以实现分页内容的合并:鼠标点选确认分页链接所在,将需要分页合并的字段项勾选上“分页合并”项即可。如果页面内具有重复子项存在,则能自动在分页中寻找该重复子项,隐含自动进行分页内容合并。
典型如上述的论坛例子,分页页面内的回复内容,可自动实现归并,此时用户只需要鼠标点选确认分页链接所在即可。有些场合下,在论坛内容页面的分页中也会同时出现主体(主表)内容,此时系统会自动进行判断,不会将主表内容当成重复子项的子表内容进行采集。
1.点击软件上的新建项目(标准),输入项目名称
2.在方框中输入 索要采集额信息列表 网址,接着点击 “开始进行预分析”,在弹出的对话框种选择“否”;选择翻页方式1。
3.然后选择信息栏种的下一页的图标,最后点击“下一步设置”
4.在选择内容页 项中,任意选择一条信息标题,然后点击“下一步设置”
5.在内容页面模板管理中,点击开始分析,在弹出的对话框种选择否
6.在左侧方框中选择帖子的标题,勾选住采集该项,及该项必须命;在存入数据库中,选择“采集存储表”,然后选择标题;
7.在采集内容页时,我们要选中内容的上部及下部,即夹在中间的是索要采集的内容,首先找到内容的上部,勾选住采集该项,及该项必须命,该项分页归并;在存入数据库中,选择“采集存储表”,然后选择内容8.在软件的“属性页”点击 如下图标 立即运行改项目,此时采集一键开始;
采集到的信息将在下方的方框中以列表的形式显示出来;此时选中任意一个信息标题,然后点击 内容页即可看到采集到的信息 标题,内容及链接。
软件特点
1.采集的对象包括文字内容、图片、flash动画视频等等2.使用自己研发的解析引擎,实现对网页源码的仿浏览器解析
3.分解网页可视化内容元素,在此基础上进行机器学习、批量采集匹配
4.支持各种类型的分页模式
5.操作简单,不懂技术也可轻松操作
功能介绍
全方位的采集功能浏览器可见的内容都可以采集。采集的对象包括文字内容,图片,flash动画视频等等各类网络内容。支持图文混排对象的同时采集。
面向对象的采集方式
面向对象的采集方式。正文和回复内容同时采集的能力,分页的内容可轻松合并,采集内容可以是分散在多个页面内。结果可以是复杂的父子表结构。
采集速度快
熊猫采集的采集速度是采集软件中最快的(之一)。不使用落后低效的正则匹配技术。也不使用第三方内置浏览器访问的技术。使用自己研发的解析引擎。
结果数据完整度高
熊猫独有的多模板功能,确保结果数据完整不遗漏。独有的智能纠错模式,可以自动纠正模板和目标页面的不一致。
JS解析的自动判断识别
现在很多网页都采用了ajax网页内容动态生成技术。此时仅仅依靠网页源码,并不能获取需要的有效内容。此时就需要对被采集的页面执行JavaScript(JS)解析,获取JS执行后的结果代码。
熊猫支持对需要JS解析的页面,执行JS解析,获取JS解析后的实际内容。鉴于执行JS解析的速度效率很低,因此熊猫内置了智能判断功能,自动检查是否需要对被采集的页面执行JS解析,如果不需要的,尽量不使用低效的JS解析模式。
多模板自动适应能力
很多网站的“内容页面”会存在多个不同种类的模板,因此熊猫采集软件允许每个采集项目可以同时设置多个内容页面参考模板,在采集运行时,系统会自动匹配寻找最合适的参考模板用来分析内容页面。
实时帮助窗口
在采集项目设置环节,系统会在窗口右上显示与当前配置相关的实时帮助内容,为使用新手提供实时帮助。因此熊猫采集软件的使用可以轻松上手。配合全程智能化辅助能力,即便是第一次接触这款软件,也可以较轻松实现采集项目的配置工作。
分页内容的轻松合并
支持各种类型的分页模式,用户只需要做两步就可以实现分页内容的合并:鼠标点选确认分页链接所在,将需要分页合并的字段项勾选上“分页合并”项即可。如果页面内具有重复子项存在,则能自动在分页中寻找该重复子项,隐含自动进行分页内容合并。
典型如上述的论坛例子,分页页面内的回复内容,可自动实现归并,此时用户只需要鼠标点选确认分页链接所在即可。有些场合下,在论坛内容页面的分页中也会同时出现主体(主表)内容,此时系统会自动进行判断,不会将主表内容当成重复子项的子表内容进行采集。
使用方法
用户名:test 密码:123456 登录即可免费使用1.点击软件上的新建项目(标准),输入项目名称
2.在方框中输入 索要采集额信息列表 网址,接着点击 “开始进行预分析”,在弹出的对话框种选择“否”;选择翻页方式1。
3.然后选择信息栏种的下一页的图标,最后点击“下一步设置”
4.在选择内容页 项中,任意选择一条信息标题,然后点击“下一步设置”
5.在内容页面模板管理中,点击开始分析,在弹出的对话框种选择否
6.在左侧方框中选择帖子的标题,勾选住采集该项,及该项必须命;在存入数据库中,选择“采集存储表”,然后选择标题;
7.在采集内容页时,我们要选中内容的上部及下部,即夹在中间的是索要采集的内容,首先找到内容的上部,勾选住采集该项,及该项必须命,该项分页归并;在存入数据库中,选择“采集存储表”,然后选择内容8.在软件的“属性页”点击 如下图标 立即运行改项目,此时采集一键开始;
采集到的信息将在下方的方框中以列表的形式显示出来;此时选中任意一个信息标题,然后点击 内容页即可看到采集到的信息 标题,内容及链接。
∨ 展开
 蓝叠(BlueStacks)安卓模拟器 v4.280.0官方版
蓝叠(BlueStacks)安卓模拟器 v4.280.0官方版 Steamcommunity 302(steam连接修复工具)v10.6绿色免费版
Steamcommunity 302(steam连接修复工具)v10.6绿色免费版 哆点v1.3.4电脑免费版
哆点v1.3.4电脑免费版 图符设计大师免费版V5.0
图符设计大师免费版V5.0
 见证者中文破解版
见证者中文破解版
 shimeji原神桌宠 V1.0 绿色免费版
shimeji原神桌宠 V1.0 绿色免费版
 Acme CAD Converter 2019v8.9.8.1489绿色汉化版
Acme CAD Converter 2019v8.9.8.1489绿色汉化版
 GIMP2(图像处理软件)v2.10.18.2中文版
GIMP2(图像处理软件)v2.10.18.2中文版
 Database.NET Prov29.5破解版(附注册信息和教程)
Database.NET Prov29.5破解版(附注册信息和教程)
 CrystalDiskInfov8.0.0中文破解版(免安装/免破解)
CrystalDiskInfov8.0.0中文破解版(免安装/免破解)
 灵墟Steam修改器 V0.8.10.16 大头猫米版
灵墟Steam修改器 V0.8.10.16 大头猫米版
 大掌柜视频号场控助手 V1010 官方版
大掌柜视频号场控助手 V1010 官方版
 yaanpv2.3.8089破解版
yaanpv2.3.8089破解版
 PingPlotter Prov5.19.1.8408破解版
PingPlotter Prov5.19.1.8408破解版
 sniffer pro(网络抓包工具)v4.9破解版
sniffer pro(网络抓包工具)v4.9破解版
 inSSIDer(无线网络信号扫描工具)v6.5中文免费版
inSSIDer(无线网络信号扫描工具)v6.5中文免费版
 凯元工具(KYTool) 32位/64位v2.8.0免费版
凯元工具(KYTool) 32位/64位v2.8.0免费版
 ADSL超频奇兵v7.1绿色版
ADSL超频奇兵v7.1绿色版